


Expressions régulières (Regex) EN VRAC
Il y a plusieurs façons d'utiliser les expressions régulières avec Delphi.
Si vous possédez Delphi XE ou une version postérieure, le plus simple est d'utiliser l'unité System.RegularExpressions.
Si vous possédez une version antérieure à Delphi XE, plusieurs possibilités s'offrent à vous. Le choix peut-être le plus recommandable est d'utiliser la classe TPerlRegEx de l'unité PerlRegEx. L'avantage de cette unité est d'être identique à l'unité System.RegularExpressionsCore livrée avec les versions récentes de Delphi (à partir de Delphi XE). Votre code sera donc réutilisable en cas de migration vers une version plus récente.
Une autre possibilité est d'utiliser la classe TRegExpr de l'unité RegExpr. L'avantage de cette unité est d'être identique à l'unité du même nom livrée avec Free Pascal. Toutefois cette unité n'est pas compatible avec les versions récentes de Delphi.
Une autre possibilité encore est d'utiliser la classe IRegex de l'unité PCRE. Il s'agit d'une unité pour Delphi 7, qui peut également être compilée avec Free Pascal.
Une autre possibilité enfin est d'utiliser la classe TFLRE de l'unité FLRE. L'avantage de cette bibliothèque est, outre sa rapidité, le fait qu'elle soit compatible aussi bien avec Delphi ancienne et nouvelle génération qu'avec Free Pascal.
On this site, you can find everything you need to know about regular expressions:
- A quick start guide bringing you up to speed with regular expressions in no time
- A complete tutorial teaching you everything about regular expressions and replacement strings
- A concise reference listing all the regular expression tokens and the flavors that support them
- A handy list of ready-to-use example regular expressions
- A helpful description of all the popular tools and languages that support regular expressions
http://edutechwiki.unige.ch/fr/Expression_r%C3%A9guli%C3%A8re
1 Définition
Les expressions régulières (abrégé expreg) aussi appelées expressions rationnelles, en anglais regular expressions (abrégé regexp), sont une écriture compacte pour représenter un ensemble (peut-être infini) de séquences de caractères semblables. Elles rappellent et étendent la notion de "Joker" ou "Wild-card" qu'on trouve dans MS-DOS (e.g. DIR *.EXE ), comme d'ailleurs dans les "shells" UNIX (sous le nom de "globbing"), ou encore Authorware.
Les expressions régulières sont une chaîne de caractères permettant de décrire un ensemble variable par l'utilisation d'une syntaxe précise, qui se retrouvent dans une foule de langages et d'outils. Pour le détail, veuillez consulter la documentation des expressions régulières. Elles diffèrent d'un environnement à l'autre par quelques détails, avec un noyau commun. Cependant, la maîtrise de cette syntaxe permet une manipulation de textes dans la majeure partie des langages de programmation.
^représente le début (d'une ligne, d'une chaîne de caractères)$représente la fin (d'une ligne, d'une chaîne de caractères).représente n'importe quel caractère*représente 0 ou plus occurrences d'un élément. Donce*représente soit "" ou "e" ou "ee" ou "eee"+représente 1 ou plus occurrences de e. Donce+représente soit "e","ee","eee", etc?représente 0 ou 1 occurrences, commes?dansvilles?qui représente l'ensemble{ "ville" , "villes" }|représente un choix entre chaînes de caractères, commela|lequi représente l'ensemble{ "la" , "le" }( )groupage d'expressions, qui permet par ex. d'écrire(e|f)gau lieu deeg|fg. Le groupage est aussi utile pour faire des substitutions (voir plus bas).[xyz]classes de caractères - un de caractères dans la liste doit être dans la cible représentée,[A-Za-z]représente toutes les lettres.
Cette dizaine de symboles et de constructions constituent un noyau commun à presque tous les modules d'expressions régulières.
(Ne correspond pas à la norme POSIX. Voir aussi la notice sur la syntaxe de citation ci-dessus ! (Par exemple dans Javascript utilisez '\\w' à la place de '\w').
\wreprésente tout caractère alphanumérique (donc qui peut faire partie d'un mot au sens formel, c.a.d. lettres et chiffres).\Wreprésente tout caractère non alphanumérique (donc qui ne peut pas faire partie d'un mot au sens formel, c.a.d. ponctuations, espaces, etc.)- Voir les manuels pour le reste.
Comment écrire des expressions régulières qui reconnaissent les signes spéciaux ci-dessus dans une chaîne de caractères ? Comme ils ont un sens spécial, ils ne peuvent se représenter eux-mêmes sans autre (ce qui est le sens normal des autres caractères). Afin de permettre de distinguer deux cas d'usage de ces caractères-là, on utilise un caractère d'échappement de code - mais sur ce point les environnements diffèrent entre eux.
- D'une part le caractère d'échappement varie, c'est
\dans le cas d'emacs, de PhP et de Perl,\\dans JavaScriptet %dans le cas du MOO.
(N.B. Les "regexps" d'emacs/PhP et du MOO ne diffèrent que par ce caractère d'échappement)
- D'autre part le choix sens normal/sens spécial en fonction de la présence ou de l'absence du caractère d'échappement varie. Dans le cas d'emacs et du MOO, les caractères:
(, |, )ont leur sens spécial lorsqu'ils sont précédés du caractère d'échappement, et leur sens normal autrement. Dans le cas de Perl et de JavaScript, c'est le contraire ! Notez également qu'il faut utiliser\\dans JavaScript ! - Enfin, certains langages (Python) permettent de stipuler quelle convention de citation on utilise.
Les séquences d’échappement suivantes sont ainsi supportées : (wikipedia)
| Séquence POSIX | Description |
|---|---|
| \b | retour arrière (correction). |
| \t | tabulation horizontale. |
| \n | saut de ligne. |
| \v | tabulation verticale. |
| \f | saut de page. |
| \r | retour chariot. |
2 Comment accéder aux expressions régulières
La recherche incrémentale par exemple avec le raccourci-clavier :C-M-s,
le remplacement incrémental avec le raccourci-clavier :C-M-%,
Chercher des lignes qui contiennent la méme regexp: voir le menu.
Il est utile d'utiliser Xemacs pour tester vos expressions faites en PHP, JS etc. Faites attention à la syntaxe de citation qui n'est pas forcément la même. Par exemple pour chercher à la fois "is" et "in" il faut utiliser i\(s\|n\).
Avec les méthodes match, replace, search de string. Voir:
- Core_JavaScript_1.5_Guide:Regular_Expressions et des Javascript Reference Guide comme RegExp and String
Pour utiliser une regexp dans JavaScript il faut d'abord la placer entre deux / / suivi de "modifieurs" Dans l'exemple ci-dessous gi veut dire d'ignorer la casse et chercher toutes les occurences dans le string: (g=global pattern matching) et (i=case-insentitive pattern matching). En ce qui concerne l'expression régulière entre les deux / /, ^[A-Z{1,} signifie qu'au début de notre suite de caractères (indiqué par ^) on cherche un nombre qui va de 1 à indéfini {1,} de lettres majuscules [A-Z]. Ensuite on définit qu'on veut un tiret \- (ici on a échappé le tiret avec un backslash), puis on s'attend à une suite de 4 ou plus {4,} chiffres [0-9]; le $ de fin nous dit qu'on ne veut aucun autre caractère après les chiffres.
var code_postal_ch = /^[A-Z]{1,}\-[0-9]{4,}$/gi;
var input_string1 = "CH-1227";
var input_string2 = "CH-12273";
Pour tester avec la méthode test d'un objet regexp
if (code_postal_ch.test(input_string1)) alert ("wow");
Pour tester avec la méthode match de l'objet string:
if (input_string1.match(code_postal_ch)) alert ("wow");
Voir le chapitre "Regular Expression Functions" et surtout les fonctions eregi(pattern, string) et ereg(pattern, string)
eregi ("(ozilla.[23]|MSIE.3)", $HTTP_USER_AGENT);
/* Returns true if client browser
is Netscape 2, 3 or MSIE 3. */
Avec le verbe match()
La fonction grep() permet de rechercher les éléments d’une liste qui présentent un pattern donné. Ainsi, pour rechercher dans une chaîne de caractères des expressions régulières avec la fonction grep, il faut fixer l’attribut « fixed » à la valeur FALSE. Exemples :
Texte1 <- c("argue", "sténo", "huons", "remet", "ponce", "mites", "ligie", "vitre", "fluée", "floué", "ahana", "fonte", "boche", "tinté", "frime", "tente", "cédez")
grep(pattern = "^a", Texte1, value = TRUE, fixed=FALSE) # Donne les mots qui commencent par la lettre « a »
grep(pattern = "e$", Texte1, value = TRUE, fixed=FALSE) # Donne les mots qui se terminent par la lettre « e »
grep(pattern = "te", Texte1, value = TRUE, fixed=FALSE) # Donne les mots qui contiennent la séquence « te »
grep(pattern = "n.e", Texte1, value = TRUE, fixed=FALSE) # Donne les mots qui contiennent la séquence « n.e »
grep(pattern = "na|ce" , Texte1 , value = TRUE, fixed=FALSE) # Donne les mots qui contiennent la séquence « na » ou la séquence « ce »
grep(pattern = "n.e|c.e" , Texte1 , value = TRUE, fixed=FALSE) # Donne les mots qui contiennent la séquence « n.e » ou la séquence « c.e »
grep(pattern = "[cdt]e" , Texte1 , value = TRUE, fixed=FALSE) # Donne les mots qui contiennent la séquence « ce » ou « de » ou « te »
grep(pattern = "[^cdt]e" , Texte1 , value = TRUE, fixed=FALSE) # Donne les mots qui contiennent la lettre « e » et qui ne présentent pas les séquences « ce », « de » et « te »
Texte2 <- c("ab","abc", "ababc", "ababab", "abababc" ,"bab","cbabab","abba","abbc","ca","abaabc", "ababbc", "acac")
grep(pattern = "ab*c" , Texte2 , value = TRUE, fixed=FALSE) # Donne les mots "abc" "ababc" "abababc" "abbc" "abaabc" "ababbc" "acac"
grep(pattern = "ab+c" , Texte2 , value = TRUE, fixed=FALSE) # Donne les mots "abc" "ababc" "abababc" "abbc" "abaabc" "ababbc"
grep(pattern = "ab?c" , Texte2 , value = TRUE, fixed=FALSE) # Donne "abc" "ababc" "abababc" "abaabc" "acac"
grep(pattern = "ab{2}c" , Texte2 , value = TRUE, fixed=FALSE) # Donne les mots qui contiennent la séquence : abbc, donc: "abbc" "ababbc"
grep(pattern = "(ab)*c" , Texte2 , value = TRUE, fixed=FALSE) # Donne "abc" "ababc" "abababc" "cbabab" "abbc" "ca" "abaabc" "ababbc" "acac"
grep(pattern = "(ab)+c" , Texte2 , value = TRUE, fixed=FALSE) # Donne les mots qui contiennent la séquence : (ab)+ c
grep(pattern = "(ab)?c" , Texte2 , value = TRUE, fixed=FALSE) # Donne les mots qui contiennent la séquence : (ab)? c
grep(pattern = "(ab){2}c" , Texte2 , value = TRUE, fixed=FALSE) # Donne les mots qui contiennent la séquence : ababc
Grep et egrep sont des outils UNIX très utiles, qui permettent de retrouver des fichiers et des lignes de texte dans des fichiers contenant un "pattern". Un usage typique sera
egrep -i -l 'd\.?k\.?s\.?|schneider' /www/*.html
Qui va afficher les noms des fichiers *.html du répertoire /www/ contenant soit les initiales "D.K.S." soit le string "schneider".
Même chose, mais en cherchant dans des sous-répertoires (ATTENTION: ce type de commande est gourmande en ressources CPU). Le résultat de la recherche est mis dans le fichier "t".
find . -name "*.html" -exec grep -il 'd\.?k\.?s\.?|schneider' {} >> t \;
- Quelques explications en plus
- le -i indique que la recherche ne doit pas tenir compte des majuscules/minuscules
- le -l indique qu'on ne veut que les noms de fichiers, sinon on a aussi toutes les lignes correspondantes (essayez)
- le *.html est un cas de "filename globbing" et pas une expression régulière
- l'expression régulière étant tapée dans le contexte du shell UNIX, il faut se méfier du fait que le shell lui-même interprète divers caractères spéciaux à sa manière. Afin d'éviter tout problème, on entoure l'expression d'apostrophes.
- Sans les apostrophes, le shell interpréterait à sa façon les caractères \ | et ? avec des résultats (presque) imprévisibles
3 Remplacement avec des expressions régulières
En dehors des recherches, les expressions régulières sont beaucoup employées pour modifier du texte de manière systématique dans un fichier. On peut se référer à des expressions groupées (...)trouvées dans un input avec une syntaxe spéciale. (Voir ci-dessus)
Dans Emacs:
M-x Replace query-replace-regexp <\(/?\)b> RET <\1em> RET remplacera tous les <b> par des <em> et les </b> par des </em>, en demandant une confirmation pour chaque apparition.
- les signes \( \) ? et \1 font partie de la syntaxe regexp d'emacs, les signes < > et / appartiennent à HTML
- le signe \1 signifie "le contenu de ce qui a été reconnu dans la 1ère paire de \( \), on peut de même employer \2, \3 etc pour faire référence à la seconde, troisième paire, etc
- ici ce contenu sera un / facultatif, selon qu'on remplace un tag <b> ou </b>;
Dans Notepad++:
Cochez "Regular expression" dans les popups pour les fonctions de recherche/remplacement.
- Voir Notepad++ Liste des Expressions Régulières sur le site the Notepad++
Dans PSPad:
Chochez "expressions régulières" dans les popups pour les fonctions de recherche/remplacement
- Voir le help (Regular expressions)
$string = ereg_replace ("$", "<BR>", $string);
/* Mettre un <BR> tag à la fin de $string. */
$string = ereg_replace ("\n", "", $string);
/* Tuer les caractères newline dans $string. */
- Pour se référer à une expression il faut utiliser
$n, par exemple $1 ou $2 ci-dessous.
input = "surf is green"; pattern = "/(\\w*) is (.*)/ig"; replyPattern = "What is so $2 about $1?"; result = input.replace(pattern, replyPattern); Ca donne result = What is so green about surf?
Perl est un langage de programmation complet, mais il admet des options d'invocations qui permettent d'accéder directement à son composant d'expressions régulières particulièrement puissant.
perl -pi.bak -e 's:<(/?)b>:<\\1em>:' mon_fichier.html
est l'équivalent de la commande emacs ci-dessus
- Malgré les apostrophes, le shell unix interprète les \ comme un caractère d'échappement, c'est pourquoi il faut écrire \\1 pour que perl obtienne \1
- -p signifie de recopier chaque ligne du fichier de l'entrée vers la sortie
- -i.bak signifie de mettre le résultat à la place du fichier original, et garder l'original en ajoutant .bak à son nom** -e 'instructions' signifie d'effectuer les instructions sur chaque ligne du fichier en cours de copie
- L'instruction de substitution a la forme s:expression:substitution:
- On peut remplacer les : par un autre caractère; le / est traditionellement utilisé, mais dans le cas présent / intervient dans le texte à remplacer.
- On peut mettre plusieurs instructions Perl entre les apostrophes, séparées par des ;
4 Modification de l'ordre dans une chaîne d'entrée dans JavaScript
L'exemple suivant illustre la formation d'expressions régulières et l'utilisation de string.split () et String.Replace () . Il nettoie une chaîne d'entrée plus ou moins formaté contenant les noms (prénom) séparés par des espaces, les tabulations et exactement une virgule. Enfin, il inverse l'ordre des noms (nom de famille en premier) et trie la liste. Le code n'a pas été testé. Se référer à l'original
/
// et peuvent avoir de multiples espaces entre les noms et prénoms.
var nom = "Harry Trump, Fred Barney, Helen Rigby, Bill Abel; Chris Hand" ;
var sortie = [ "---------- chaîne originale \n" , nom + "\n" ] ;
// Préparer deux modèles d'expressions régulières et de stockage de tableau.
// Diviser la chaîne en éléments de tableau.
// Motif: possible l'espace blanc puis virgule puis de l'espace blanc possible
var motif = /\s*;\s*/;
// Pause de la chaîne en morceaux séparés par le schéma ci-dessus et
// Stocker les morceaux dans un tableau appelé nameList
var nameList = noms.split ( motif ) ;
// Nouveau modèle: un ou plusieurs caractères, puis des espaces, les caractères.
// Utilisez les parenthèses pour "mémoriser" des parties du modèle.
// Les parties mémorisées sont appelées plus tard.
motif = /(\w+)\s+(\w+)/;
// Nouvelle gamme pour la tenue de noms en cours de traitement.
var bySurnameList = [ ] ;
// Affichage du tableau de nom et remplir le nouveau tableau
// Avec les noms séparés par des virgules, dernier premier.
//
// La méthode replace enlève rien correspondant au modèle
// et la remplace par la chaîne-deuxième partie mémorisée mémorisé
// suivi de l'espace virgule suivie première partie mémorisée.
// Les variables $1 et $2 se réfèrent à des parties
// mémorise tout en faisant correspondre le motif.
sortie.push ( "---------- après division par expression régulière" ) ;
var i, len;
for (i = 0, len = nameList.length; i < len; i++){
sortie.push(nameList[i]);
bySurnameList[i] = nameList[i].replace(pattern, "$2, $1");
}
// Affichage de la nouvelle gamme.
sortie.push ( "---------- noms inversé" ) ;
for (i = 0, len = bySurnameList.length; i < len; i++){
sortie.push(bySurnameList[i]);
}
}
// Tri par nom, puis afficher le tableau trié.
bySurnameList.sort ( ) ;
sortie.push ( "---------- Classé" ) ;
for (i = 0, len = bySurnameList.length; i < len; i++){
sortie.push(bySurnameList[i]);
sortie.push ( "---------- End" ) ;
console.log ( sortie.join ( "\n" ) ) ;
Travailler avec les expressions régulières :
5 Aide mémoire
Métacaractères
| caractère | signification |
|---|---|
| ^ | début de la chaîne |
| $ | fin de la chaîne |
| . | n'importe quel caractère sauf retour à la ligne |
| * | matche 0 ou plusieurs fois |
| + | matche au moins 1 fois |
| ? | matche 0 ou 1 fois |
| alternative | |
| () | groupement; mémorisation |
| [] | jeu de caractères |
| {} | répétition |
- [1] (Travailler avec les expressions régulières)
Répétition
| caractère | signification |
|---|---|
| a* | zéro ou plusieurs a |
| a+ | un ou plusieurs a |
| a? | zéro ou un a |
| a{m} | exactement m a |
| a{m,} | au moins m a |
| a{m,n } | au minimum m a et au maximum n a |
6 Les expressions régulières ont une puissance limitée
(un peu de philosophie ....)
Il y a une foule de modèles d'ordinateurs et de langages de programmation. Néanmoins, d'un point de vue théorique (c'est-à dire en ignorant les questions de performance et de limitation de mémoire) toutes ces machines (et langages) sont équivalentes, en ce sens qu'il est en principe possible de simuler chaque machine ou langage au moyen d'un programme (dit émulateur ou interpréteur) tournant sur une autre machine/langage. Ce fait est bien illustré, d'ailleurs, par les divers émulateurs Windows tournant sur Sun ou Mac.
De manière générale, les langages de programmation appartiennent à cette classe, dite de "la machine universelle". Les expressions régulières sont le cas d'exception d'un modèle de machine formellemoins puissant que la machine universelle mais néanmoins très utile et employé. Mais le plus souvent comme un "sous-langage", compartiment d'un langage plus puissant.
Un exemple de tâche simple mais hors de portée du langage des expressions régulières : vérifier que les paires de parenthèses correspondent.
(.*) va admettre 1) "(x)" et 2) "(x))
([^)]*) élimine 2) mais admet 3) "((x)"
([^()]*) reconnaît correctement une paire de parenthèses mais n'autorise pas 4: "((x))"
En fait, il est possible d'écrire des expressions régulières qui vont reconnaître les chaînes de caractères ayant un nombre maximum prédéterminé de parenthèses imbriquées. Ecrivez-en une qui reconnaît deux niveaux de parenthèses.
7 Liens
- Expression rationnelle (Wikipedia fr)
- regular-expressions.info. Portail dédié aux regexps. Inclut un "quickstart", un tutoriel, des exemples etc.
- Rubular.com Portail pour tester en ligne les expressions régulières.
- Éditeur Emacs
- Regular Expression Search (copie d'une page info de Emacs)
- Une aide complète sur (X)Emacs est disponible dans "Help->Info" (d'où ce texte a été tiré).
- Éditeur Notepad++
- PHP
- Regular Expression Functions (Perl-Compatible, Manuel PHP)
- Regular Expression Functions (POSIX Extended, manual)
- JavaScript
- Core_JavaScript_1.5_Guide:Regular_Expressions
- Introduction to Regular Expressions (microsoft)
- RegExp
- Cours Java expressions régulières
- Autre cours Java expressions régulières
- MOOs
- Tapez 'help regular'
- Le MOO Programming Manual
- Perl
- Perl et PHP (variante "Perl"), voir: Regular Expression Functions
- Python
- Regular Expression HOWTO, par A.M. Kuchling
- Outils Unix
- Regular Expressions Cheat Sheet by LoveJackDaniels.com / Dave Child.
- regexpal.com (Regexp tester, entrez une regexp et des exemples et testez)
- regular-expressions.info (inclut des exemples qu'on cherche souvent, par exemple une adresse email).
- Génériques
- Les Symboles dans les Expressions Régulières (expreg.com)
- Expression rationnelle (Wikipedia)
- JavaScript (f)
- JavaScript (en)
- String Matching And Replacing In Javascript 1.2 By Angus Davis
- String Regular Expressions with JavaScript and ECMAScript (regular-expressions.info). Ceci est plus un manuel qu'un tutoriel
- Chatterbot MOO / Javascript
- Simple Chatterbot (fait par DSchneider pour ses cours).
- Some explanations for the chatter bot
- Page Edutechwiki sur les chatterbots (esquisse à complèter)
Quelques exemples d'implantation de robots de conversation dans les bibliothèques européennes :
- Stella : chatterbot de la Staats- und Universitätsbibliothek Hamburg
- Bob : chatterbot de la Libera Università di Bolzano
- Kornelia : chatterbot de la Kornhausbibliothek de Berne
- PHP
- expreg.com Les expressions régulières en PHP. C'est carrément un portail dédié à cela ....
- Validation de formulaires HTML (Javascript, liens dans EduTechwiki Anglais). See also some code we copied here
http://astuces.jeanviet.info/bureautique/rechercher-et-remplacer-du-texte-avec-notepad-et-quelques-regex.htm
Voki quelques exemples de ce que peuvent faire les regex :
- Trouver dans un texte toutes les phrases qui commencent par "il était une foie" et remplacer le texte par "Il était une fois" (^il était une foie)
- Chaque fois qu’un texte se termine par un point, on peut forcer un retour à la ligne (.$)
- Trouver dans un texte tous les mots qui contiennent 2 o consécutifs (.*oo.*)
 Les Principales Regex à utiliser avec notepad
Les Principales Regex à utiliser avec notepad
| regex | effet | exemple |
|---|---|---|
| . | pour remplacer un caractère | ex: "jeanvie." va trouver "jeanviet" et "jeanvier" |
| […] | pour indiquer un ensemble de caractère | ex: "[éèêë]" pour trouver un accent |
| [^…] | pour indiquer des caractères complémentaires | ex: "[^0-9]" pour trouver tout ce qui est différent d’un chiffre |
| ^ | pour indiquer que le caractère doit être au début d’une ligne | ex: "^jeanviet" pour trouver toutes les lignes qui commencent par jeanviet |
| $ | pour indiquer que le caractère doit être en fin de ligne | ex: "jeanviet$" pour trouver toutes les lignes qui se terminent par jeanviet |
| .* | n’importe quel nombre de caractère entre deux caractères | ex:"j.*t" trouvera jeanviet, jet, jouet |
Conserver le texte d’une regex
Soit ces 4 lignes de texte :
- mois : janviet 2010
- mois : février 2010
- mois : mars 2010
- mois : avril 2010
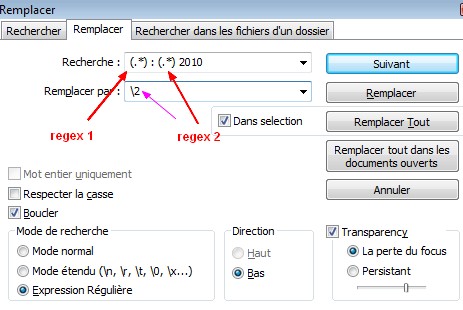
Je ne veux garder que le mois, c’est à dire jeanviet, février, mars, avril. On va donc supprimer tout ce qui se trouve avant les " : " et l’année " 2010" et conserver le mois entre les deux.
Voici la manip sous notepad :
http://www.expreg.com/symbole.php
Les Symboles dans les Expressions Régulières
Nous allons dans cette partie vous donner et vous expliquer les différents symboles utilisés dans les expressions régulières.
Une des premières choses à réaliser dans la conception d'une expression régulière, c'est de définir le motif (pattern en anglais)
Pour construire ces motifs, vous avez besoin de créer une structure formée de caractères littéraux, puis de symboles qui sont définis en tant que métacaractères et délimiteurs et qui seront utilisés séparément ou en combinaison à l'intérieur d'un même groupement ou d'une classe.
Oups, me direz-vous... je suis déjà largué là !
Aucune inquiétude, on va développer le sujet.
1) Les caractères littéraux : On appelle littéral une valeur qui est écrite exactement comme elle est interprétée.
Exemple :
| Littéraux | Signification |
| a | correspond à la lettre "a" et rien d'autre |
| chat | correspond au mot "chat" et rien d'autre |
| toto | correspond au mot "toto" et rien d'autre |
Vous constatez que les littéraux permettent une identification exacte et précise du motif recherché. L'intérêt des expressions régulières ne serait pas bien grand si elles étaient limitées à cette seule possibilité. De plus, pour une recherche simplifiée, une fonction comme strpos() le fera bien plus rapidement qu'un simple preg_match(). Il existe heureusement des symboles spécifiques qui ont un sens plus général et que nous présentons dans la suite de ce cours.
L'accent circonflexe ^ et le symbole dollar $ et enfin le point .
| Symbole | Description |
| ^ | Indique le début de la chaîne - exemple ^chat reconnaît une ligne qui commence par chat |
| $ | Indique la fin de la chaîne - exemple : chat$ reconnaît une ligne qui finit par chat |
| . | Le point indique n'importe quel caractère |
Ces symboles sont des métacaractères : >>> cf -> Qu'est ce qu'un métacaractère ?
Ils sont au nombre de trois :
le point d'interrogation (?), l'étoile (*) et le plus (+)
| Symbole | Description |
| * | Indique 0, 1 ou plusieurs occurrences du caractère ou de la classe précédente |
| + | Indique une ou plusieurs occurrences du caractère ou de la classe précédente |
| ? | Indique 0 ou une occurrence du caractère ou de la classe précédente |
Ces symboles sont des métacaractères : >>> cf -> Qu'est ce qu'un métacaractère ?
Bof... oui... mais encore ?
On va travailler avec des exemples, c'est le but du jeu et, selon l'adage, un petit dessin vont mieux qu'un long discours.
Exemple :
a* correspond à aucune ou plusieurs occurrences de la lettre (a)
soit pas de a, ou a, aa, aaa, aaaa, etc...
a+ correspond à une ou plusieurs occurrences de la lettre (a)
soit au moins un a ou aa, aaa, aaaa, etc...
a? correspond à 0 ou une seule occurrence de la lettre (a)
soit a ou pas de a
Ce sont les accolades { }
| Exemple | Signification |
| a{3} | correspond exactement à aaa |
| a{2,} | correspond à un minimum de deux a consécutifs soit aa, aaa, aaaaa.... |
| a{2,4} | correspond uniquement à aa, aaa, aaaa |
Ces symboles sont des métacaractères : >>> cf -> Qu'est ce qu'un métacaractère ?
Délimitées grâce aux crochets [ ]
| Exemple | Signification |
| [..-..] | Le tiret représente l'intervalle à l'intérieur de la classe Il s'agit d'un métacaractère s'il est placé dans cette position. Pour permettre sa lecture en tant que caractère "tiret" il convient de le placer en début de la classe comme ceci [-....] |
| br[iu]n | ce qui signifie, trouver br suivi de i ou de u suivi de n comme brun ou brin |
| exemple de recherche sur une balise de titre <h1> <h2> <h3>, etc... |
|
Ces symboles sont des métacaractères : >>> cf -> Qu'est ce qu'un métacaractère ?
| Classe | Signification |
| [[:alpha:]] | n'importe quelle lettre |
| [[:digit:]] | n'importe quel chiffre |
| [[:xdigit:]] | caractères héxadécimaux |
| [[:alnum:]] | n'importe quelle lettre ou chiffre |
| [[:space:]] | n'importe quel espace blanc |
| [[:punct:]] | n'importe quel signe de ponctuation |
| [[:lower:]] | n'importe quelle lettre en minuscule |
| [[:upper:]] | n'importe quelle lettre capitale |
| [[:blank:]] | espace ou tabulation |
| [[:graph:]] | caractères affichables et imprimables |
| [[:cntrl:]] | caractères d'échappement |
| [[:print:]] | caractères imprimables exceptés ceux de contrôle |
Réalisé avec la barre | et le tiret - et l'accent circonflexe ^ à l'intérieur des crochets [ ]
La barre verticale | peut également être positionnée entre des parenthèses dans la recherche du motif (voir * dans le tableau exemple)
Exemple :
| Exemple | Signification |
| \<h[1-6]\> | intervalle de recherche de 1 à 6 - affichera les balises de titre <h1> <h2> etc...
|
| [0-9] | tous les chiffres de 0 à 9, etc... |
| p(ai|i)n | la barre verticale détermine une alternative ce qui signifie tout ce qui s'écrit pain ou pin |
| L'alternative dans le motif lui-même | |
| ^(De|A):@ | détermine une alternative dans le motif ce qui signifie tout ce qui commence par De:@ ou A:@ |
| La classe complémentée | |
| [^1] | classe complémentée ce qui signifie reconnaître tout sauf ce qui est énuméré, ici, tout sauf le chiffre 1 |
| [^1-6] | classe complémentée ce qui signifie reconnaître tout sauf ce qui est énuméré, ici, tout sauf les chiffres de 1 à 6 |
Ces symboles sont des métacaractères : >>> cf -> Qu'est ce qu'un métacaractère ?
Tableau récapitulatif
| . | le point | n'importe quel caractère |
| [...] | classe de caractères | tous les caractères énumérés dans la classe |
| [^...] | classe complémentée | Tous les caractères sauf ceux énumérés |
| ^ | circonflexe | positionne le début de la chaîne, la ligne... |
| $ | dollar | marque la fin d'une chaîne, ligne... |
| | | barre verticale | alternative - ou reconnaît l'un ou l'autre |
| (...) | parenthèse | utilisée pour limiter la portée d'un masque ou de l'alternative |
| * | astérisque | 0, 1 ou plusieurs occurrences |
| + | le plus | 1 ou plusieurs occurrence |
| ? | interrogation | 0 ou 1 occurrence |


/https%3A%2F%2Fassets.over-blog.com%2Ft%2Fcedistic%2Fcamera.png)
/http%3A%2F%2Fwww.developpez.net%2Fforums%2Fattachments%2Fp603863d1%2Fa%2Fa%2Fa)